
Stable Diffusion 3 Mediumをweb UIで利用する方法です。
気がついたらweb UIでStable Diffusion 3がサポートされてました。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.10.0
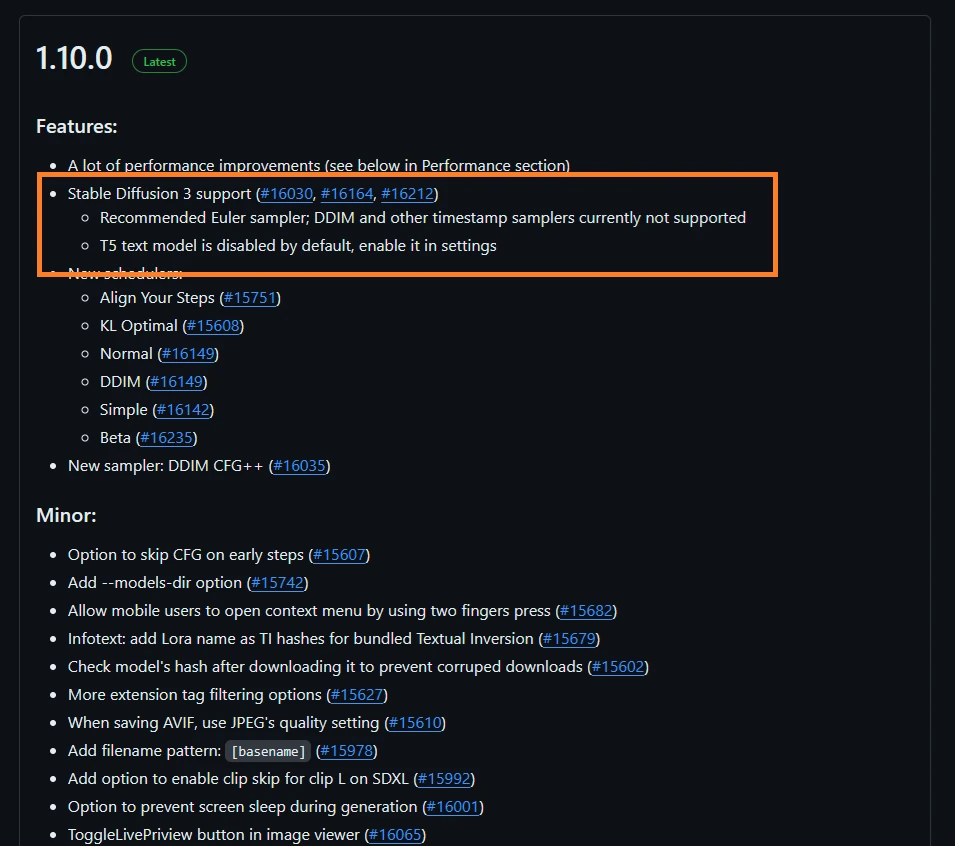
ちなみにモデルが超重いので並のGPUでは動かない可能性があります。
Stability AIの説明だとVRAM24GB推奨。それか設定を最適化すれば動くらしい。
実質xx90番台専用。僕はRTX3090で遊んでます。
導入の敷居が高すぎる...
POINTxformersを利用すれば実行時のVRAMは10GBくらい。
また、動作にはStable Diffusion web UIが必要になります。
以下にインストール手順をまとめてるので参考にしてください。
◆ Stable Diffusion web UIのインストール方法について
Stable Diffusion web UI + WSL + Ubuntuの環境を構築する
純正のStable Diffusionをコマンド実行するのは実用的に厳しいです。なので、最も人気のあるStable Diffusion web UIをWSLとUbuntuの環境に構築したいと思います。 [20240303]環境構築後にCUDA ToolkitやcuDNNを更新する方法です。本記事のバージョンが合わない場合、...
◆ CUDA ToolkitやcuDNNを更新する方法について
CUDA ToolkitとcuDNNを更新する方法 (WSL+Ubuntu環境)
Stable Diffusionで利用するNVIDIA関連のツールを更新する方法です。CUDA ToolkitやcuDNN等、新しい機能を利用するためには更新が必要だったりします。 何となく環境が古くなってきたので関連する部分を更新しました。 対応するバージョンの確認 CUD...
Stable Diffusion web UIをアップデート
最初にweb UIをStable Diffusion 3がサポートされた1.10.0以上に更新します。
更新方法はいつもと同じです。以下の記事を参考に本体や拡張機能を更新してください。
Stable Diffusion web UIを更新する方法 (WSL+Ubuntu環境)
Stable Diffusion web UIをアップデートする方法です。何となく、ちゃんとまとめました。無理に最新版にする必要もないのですが、新機能が増えたりするので好みで更新してください。 [20240821]更新でErrorが発生した場合の対処方法を追加しました。 ◆ Stable Diffu...
学習モデルの追加方法
モデルのダウンロード
学習モデルは以下からダウンロードします。
https://huggingface.co/stabilityai/stable-diffusion-3-medium
ただし、Hugging Faceにログインして情報提供に同意しないとモデルはダウンロードできません。
ログイン状態であれば、こんな画面になります。required(必須)を埋めて1番下のAgreeなんちゃらで同意します。
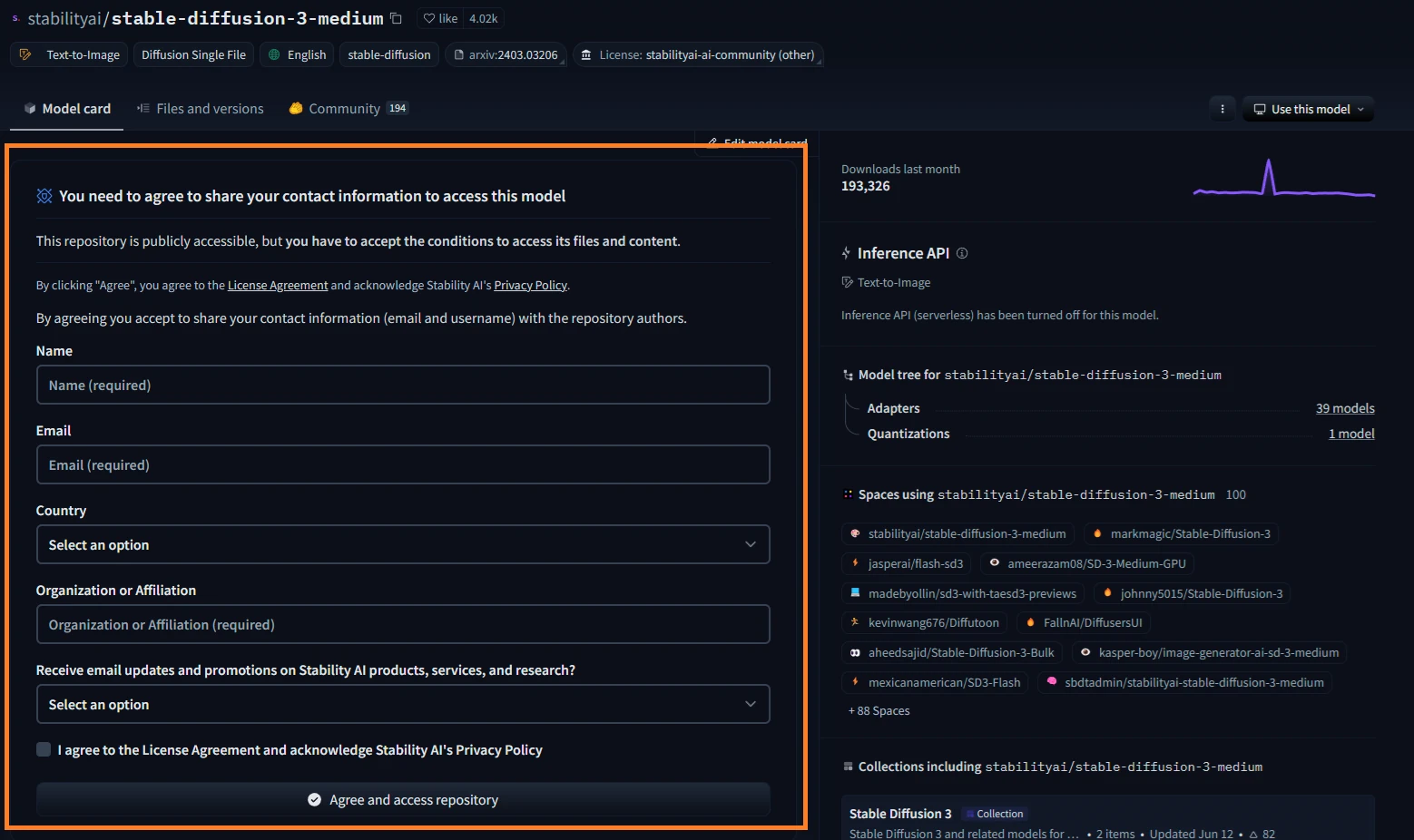
| 項目 | 概要 |
|---|---|
| Name | 名前を入力する。 |
| メールアドレスを入力する。 | |
| Country | 国を選択する。つまりJapanを選択する。 |
| Organization or Affiliation | 所属する組織を入力する。個人ならprivate等。 |
| Receive email . . . | きっとメーリングリストへの登録。不要ならNoを選択する。 |
| I agree to the License . . . | ライセンスへの同意。チェックする。 |
Hugging Faceに登録する場合https://huggingface.co/join
同意すると、こんな感じの画面になります。
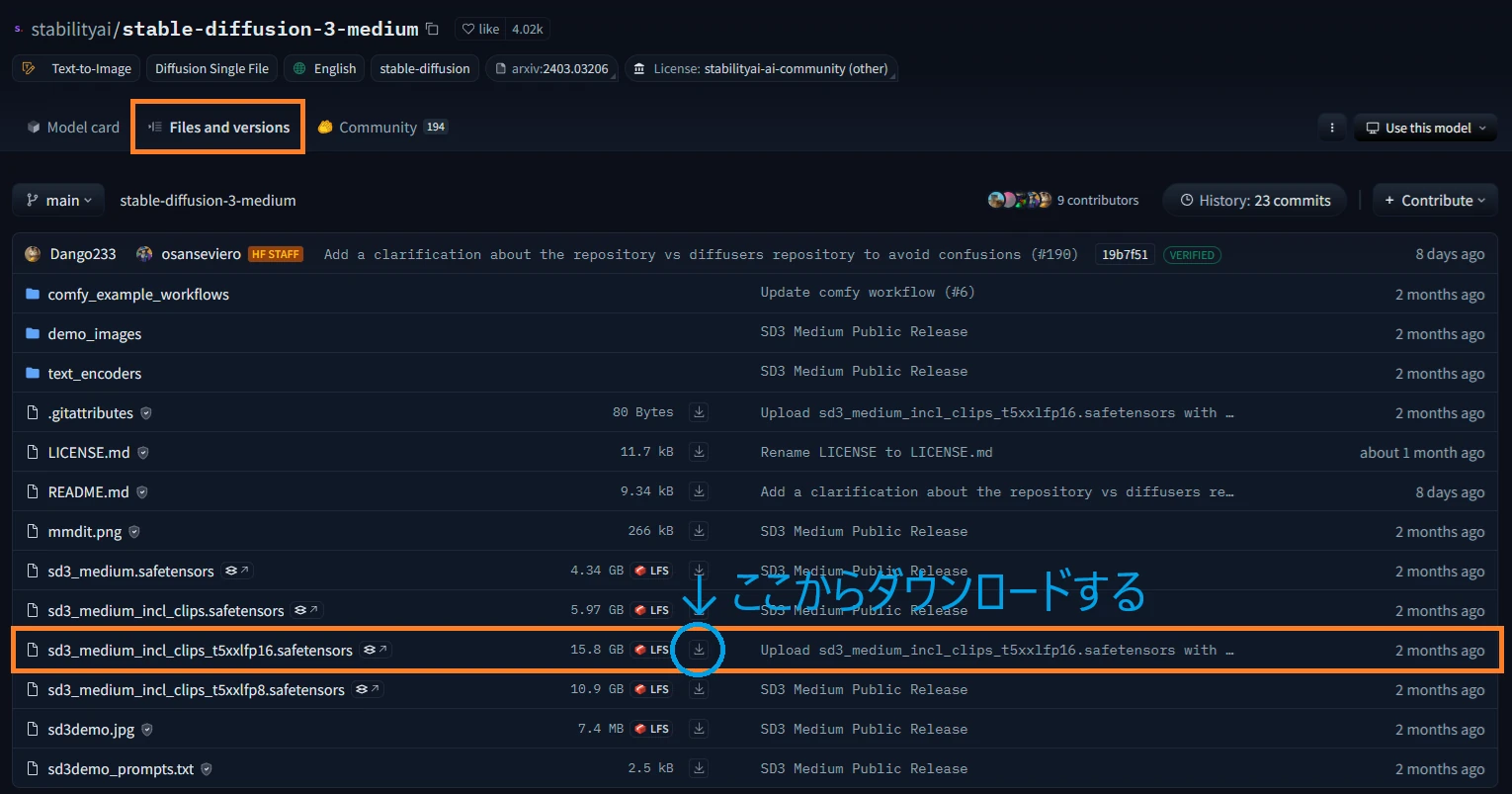
次にFiles and versionsを選択します。
そして表示されたファイル群の中から以下のモデルをダウンロードします。
sd3_medium_incl_clips_t5xxlfp16.safetensors
モデルには種類があって、さっきのは全盛りフル版です。
サイズが大きすぎて動かない場合は以下のモデルなら動くかも。
sd3_medium_incl_clips_t5xxlfp8.safetensors
他のモデルに軽そうなのがありますが、Text Encoderが含まれないので動きません(たぶん)。
何らかの理由でファイルを分離させたい人はtext_encodersの中から適当に選別してください。
モデルの配置
モデルを入手したら、いつもと同じくモデル用の指定フォルダに配置します。
WSLはエクスプローラから直接アクセスできるので、その機能を使ってモデルを配置します。
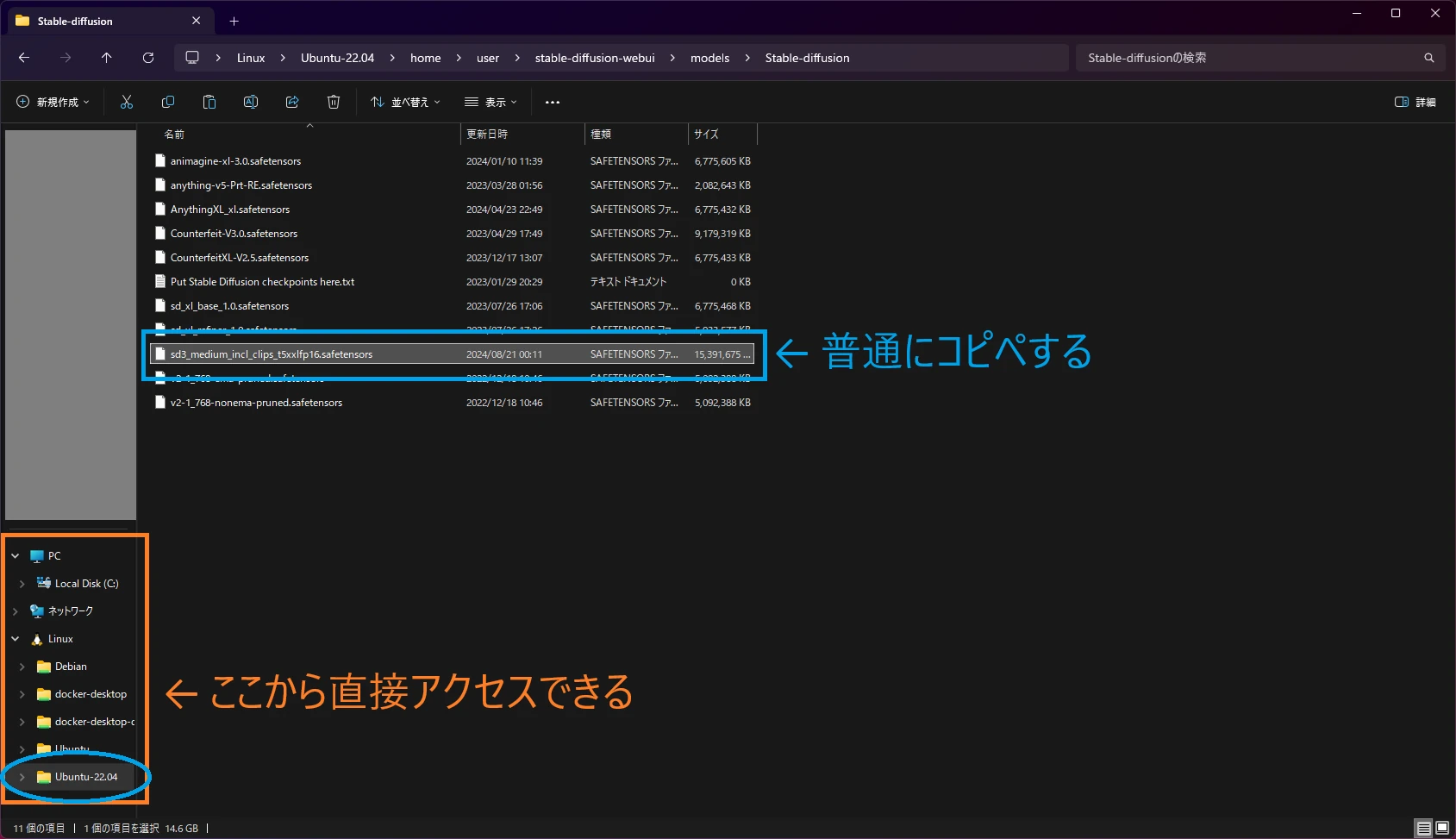
僕のセットアップ方法を参考にした場合はここ。
\\wsl.localhost\Ubuntu-22.04\home\user\stable-diffusion-webui\models\Stable-diffusion
推奨設定
英語なんで僕が雑に翻訳します。
信頼度は低いよ。
アスペクト比
Default値は1024x1024です。
Steps数
Default値は50です。ただ、num_inference_stepsなので通常のステップ数では無いかも。
Scale数
Default値は7.0です。
NegativePrompt
モデルが未トレーニングの場合は利用不可能。
参考プロンプトも空白なので、SD3M標準モデルでは機能しないと思う。
生成画像

ParametersSampler: Euler, Schedule: Automatic, Steps: 50, CFG scale: 7, Seed: 2090557890, Size: 1024x1024, Model: sd3_medium_incl_clips_t5xxlfp16
Prompta picture of a cat holding a sign that says hello world
NegativePrompt未使用

ParametersSampler: Euler, Schedule: Automatic, Steps: 50, CFG scale: 7, Seed: 2903536720, Size: 1024x1024, Model: sd3_medium_incl_clips_t5xxlfp16
PromptGorilla holding a sign in one hand that reads "I am human"
NegativePrompt未使用

ParametersSampler: Euler, Schedule: Automatic, Steps: 50, CFG scale: 7, Seed: 3610440269, Size: 1024x1024, Model: sd3_medium_incl_clips_t5xxlfp16
PromptInfinite stars shining in a beautiful galaxy
NegativePrompt未使用

ParametersSampler: Euler, Schedule: Automatic, Steps: 50, CFG scale: 7, Seed: 2607240578, Size: 1024x1024, Model: sd3_medium_incl_clips_t5xxlfp16
PromptAnime drawing of a beautiful vampire girl living in a beautiful castle
NegativePrompt未使用

ParametersSampler: Euler, Schedule: Automatic, Steps: 50, CFG scale: 7, Seed: 4251993704, Size: 1024x1024, Model: sd3_medium_incl_clips_t5xxlfp16
PromptAn anime drawing of a beautiful girl playing with animals on a summer prairie saying "hello"
NegativePrompt未使用
あとがき
プロンプトの文字を識別できるのが進化した部分かな。ただ、手足はまだまだ化け物ですね。
ここはSD3MかつNegativePromptに対応したモデルが出てくれば解決するんじゃないかな。
公式推奨はVRAM24GBだけど、xformers使えば10GBくらいだからxx80番台でも動くんじゃね。
それ以下のGPUはもっと最適化が進まないと無理かも。急ぎ遊びたい人はGPUを買おう。
RTX4090が高すぎるのが問題。
$1600くらいなのにね。
通貨安の責任を取って全国民にRTX4090配布しろ。
この記事は参考になりましたか?
コメント